





With the increased use of digital platforms like— IoT devices, social media, and cloud technologies, modern businesses generate large amounts of data from various sources. When consolidated and transformed efficiently, this data can be used to make better decisions, improve operational efficiency, and gain a competitive advantage in an increasingly data-driven world.
Data collected from diverse source systems, once centralized and made available for analysis, can address unique business challenges and requirements. These include advanced scalability, accessibility, and a need to better understand core business, customers, and market dynamics.
In this data-driven decision-making age, data lakes have emerged as powerful solutions. They store all data types in any volume without the need for prior transformation, making the data available for analysis when needed. In this comprehensive guide, we will explore data lake management and its fundamentals for scaling, storing, and accessing large volumes of diverse data types.
What is a Data Lake? A Brief Introduction!
Data Lake is a centralized data repository that allows organizations to store data of any kind, from any source, and with any data format or architecture. Data, whether structured, unstructured, or semi-structured, can be stored as they are without the need for pre-formatting or organizing them.
Later, you can apply various analytics on data as per the requirements, such as:
- Dashboards and Visualizations: Create visual representations of your data to monitor performance and trends.
- Big Data Processing: Handle large-scale datasets efficiently for deeper analysis.
- Real-time Analytics: Analyze data as generated, enabling immediate insights and actions.
- Machine Learning: Use the data for predictive modeling or automated decision-making to support more intelligent, data-driven decisions.
This flexibility enables faster and more diverse analysis without the need for prior data preparation.
Data lakes hold key importance in today’s digital age. But why?
Data-driven organizations generate better value from their data and outdo their competition. They are 23 times more likely to acquire customers, 6 times more likely to retain customers, and 19 times more likely to be profitable. Information and analytics are critical aspects of enterprises, and 90% of the organizations mention that it helps them build significant competency.
Moreover, business leaders use advanced analytics, such as machine learning, on new data sources like log files, click-stream data, and social media. Data from internet-connected devices is also stored in a data lake.
Data lake management allows businesses to identify and seize business opportunities quickly by leveraging analytics. This enables them to attract and retain customers, improve productivity, maintain devices proactively, and make more informed decisions, ultimately driving business growth.
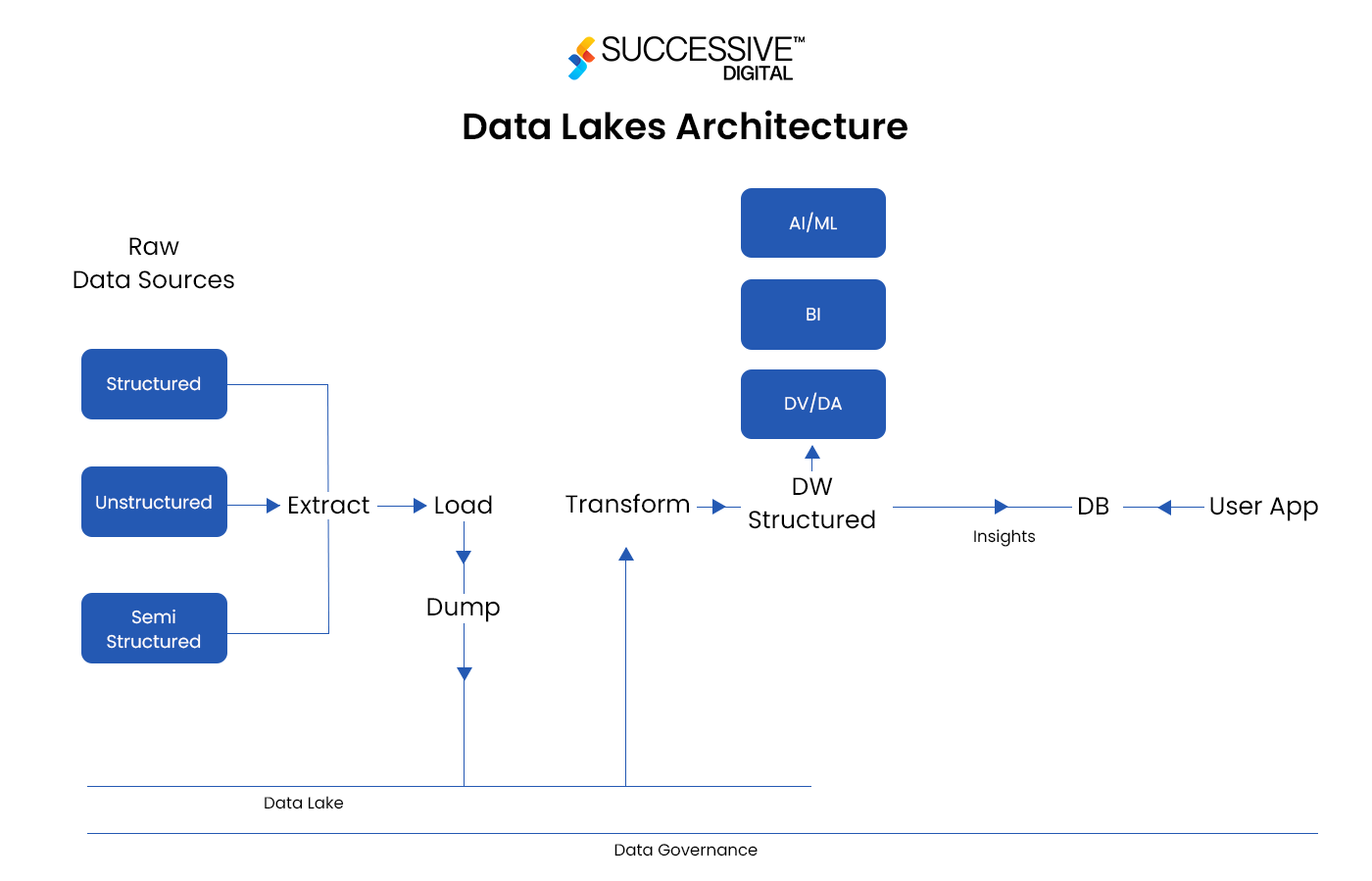
Data Lake Architecture and Key Components
Data Ingestion
This is a process of importing data into the data lake from various sources and forms, either in batch or real-time modes, before undergoing further processing.
In batch ingestion, a scheduled, interval-based data importation method is used— transferring large chunks of data at a time.
- Tools used: Apache NiFi, Flume, and traditional ETL tools– Talend and Microsoft SSIS
On the other hand, real-time ingestion can transfer the data as it is generated, effective for time-sensitive applications like fraud detection or real-time analytics.
- Tools Used: Apache Kafka and AWS Kinesis
The ingestion layer uses a variety of protocols, APIs, or connection methods to provision heterogeneous data sources and ensure a smoother data flow.
Storage Layer and Data Processing
This is where data is stored and transformed, making it more accessible and valuable for analysis. Divided into different zones, this layer ensures ease of management and workflow efficiency.
The initially ingested data lands in the raw data store section in its native format— structured, semi-structured, or unstructured. It acts as a repository for data staging before transformation.
Solutions used: Hadoop HDFS, Amazon S3, or Azure Blob Storage.
In data lake management, where data undergoes transformation, that layer is called the transformation section, which supports both batch and stream processing. A highly versatile layer where different transformation processes occur, such as:
- Data Structuring: Breaking down unstructured or semi-structured data into a form suitable for analysis.
- Data Cleansing: Removing or correcting inaccurate records, discrepancies, or inconsistencies in the data.
- Data Enrichment: Adding value to the original data set by incorporating additional information or context.
- Data Normalization: Modifying data into a standard format, ensuring consistency.
After transformation, the data becomes trusted data, which is reliable, clean, and suitable for analytics and machine learning models. This trusted data is then moved to another zone called the refined or conformed data zone, where additional transformation and structuring may occur.
- Tools Used: Dremio or Presto
Refined data is more accessible, easier to work with, and used by analysts and data scientists for analytics, business intelligence, and machine learning tasks. In this layer, data changes from raw to a refined or conformed form with a streamlined data pipeline, ensuring organizations can derive actionable insights efficiently and effectively.
Data Governance and Security
An overarching layer of governance, security, and monitoring is integral to maintaining the security of data flow. This layer is typically implemented through a combination of configurations, third-party tools, and specialized teams.
It establishes and imposes rules, policies, and procedures for data access, quality, and usability, ensuring information consistency and responsible use.
- Tools Used: Apache Atlas or Collibra
Moreover, security protocols are needed to safeguard against unauthorized data access and ensure compliance with data protection regulations.
Solution Implemented: Varonis or McAfee Total Protection
ETL/ELT
These two processes are used to move data from source systems into the data lake. In ETL, data is transformed before loading, while in ELT, it is loaded into the data lake and transformed later as needed for analysis. This flexibility ensures data lake management occurs in the most efficient manner for business requirements.
Data Catalog
A data catalog is crucial for managing the vast and diverse data stored in a data lake. It organizes and tags data for easy search, access, and discovery, helping users find relevant information quickly. Tools like AWS Glue Data Catalog and Azure Data Catalog are commonly used to automate this process, providing metadata management and data lineage.
Analytics
With data lake management, organizations can perform advanced analytics by enabling the collection and processing of massive amounts of raw data. Analytics can range from simple reporting to complex ML models. Common tools used include Apache Spark and Presto, which allow businesses to run large-scale queries and data processing directly on their data lake.
Machine Learning
Data lakes serve as the foundation for machine learning models, allowing businesses to train algorithms with vast datasets. Whether it’s predictive maintenance, customer churn analysis, or fraud detection, the scalability of cloud-based data lakes makes it possible to analyze data in real-time and extract actionable insights.
Data Movement
With data lake management, you can import any amount of data in real-time from multiple sources and in its original format. It saves time and effort in defining data structures, schema, and transformations, allowing you to scale to data of any size.
The Benefits of a Well-Managed Data Lake for Enterprises
Data Centralization and Flexibility
As a centralized repository, Data Lakes can store data in its native format and collect from a variety of sources, whether it is business applications, mobile apps, IoT devices, social media, or streaming. Moreover, it does not require to be structured or defined before it is used for analytics, providing better flexibility.
Scalability and Cost-Effectiveness
Cloud-based data lakes offer unmatched scalability, allowing you to store and process unlimited data volumes. By utilizing services like AWS Data Lake, Google Cloud Data Lake (GCP), or Azure Data Lake, enterprises can dynamically scale resources up or down based on current demands. This ensures cost-efficiency, as companies only pay for the storage and computing resources they actively use. Such elasticity makes it easier to manage large-scale data operations while maintaining financial oversight.
Improved Data Accessibility
A well-structured data lake management process simplifies data accessibility, enabling various teams—analysts, data scientists, and business users—to easily pull the data they need. The lake supports all data types, making it easier to extract, transform, and load (ETL) data into analytics tools or data warehouses, ensuring that insights can be generated quickly without delays in data preparation.
Managing Analytics in Real Time
Data lakes are designed to support real-time analytics, where data is processed and analyzed as it’s ingested. This enables enterprises to act quickly on current data, making informed decisions faster, improving operational efficiency, and delivering immediate insights. With Azure Data Lake or AWS Kinesis, for example, you can run real-time dashboards and analytics applications on streaming data, such as IoT sensor data or live customer interactions.
Best Practices for Managing Data Lakes Effectively
Strong Data Governance Framework
With the implementation of clear policies for data access, quality, and security, you can ensure a robust and up-to-date cloud infrastructure. Use governance tools like Apache Atlas or Collibra to ensure data is consistently managed and compliant with industry regulations.
Automated Data Ingestion and Processing
Automating data ingestion and ETL processes reduces manual errors and improves efficiency. Tools like Apache NiFi, AWS Glue, or Azure Data Factory help streamline the flow of data into your lake.
Optimizing Storage
Organize and store data in different layers based on its usage—raw, processed, and refined zones. With effective storage solutions such as Amazon S3 or Azure Blob Storage can be used to balance performance and cost.
Security Best Practices
Implement strong encryption, access controls, and auditing mechanisms. Cloud providers like AWS and Azure offer integrated security solutions such as AWS KMS and Azure Key Vault to protect sensitive data.
Monitoring and Maintenance
Regular monitoring is essential for optimizing performance and detecting issues early. Cloud-native tools like AWS CloudWatch and Azure Monitor provide insights into data lake operations and help maintain health.
Design for Scalability
Ensure your data lake architecture can scale smoothly as data volumes grow. Consider distributed storage and computing solutions to handle spikes in demand without degrading performance.
Data Retention Policies
Develop a robust data retention strategy to archive or delete old/obsolete data. This keeps the data lake lean and cost-effective, ensuring that only valuable data is retained.
Metadata Management
With metadata management tools, in data lake management, like AWS Glue or Azure Data Catalog, you will be able to tag and organize data effectively. Hence, they quickly find and access the needed data without having to go through massive datasets.
Data Analytics and Visualization
You can simplify the use of data for applications through interactive reports and dashboards by connecting your data lake to analytics platforms and BI tools like Tableau and PowerBI. Thus, enabling users to visualize and gain insights from the data, driving better decision-making.
Navigating Essential Tools and Technologies for Effective Data Lake Management
Cloud-Based Solutions
Popular cloud-based solutions like Amazon S3, Azure Data Lake, and Google Cloud Storage (GCP Data Lake) offer highly scalable and secure storage options for building and managing data lakes.
Ingestion and ETL Tools
Solutions like Apache NiFi, AWS Glue, and Azure Data Factory simplify the process of ingesting and transforming large volumes of data.
Governance and Security Tools
Use governance and cataloging tools like Apache Atlas and AWS Glue Data Catalog to manage data quality and security effectively. Integrated security solutions for data lakes like AWS KMS and Azure Key Vault provide secure encryption services for sensitive data.
Analytics Tools
Big data analytics tools such as Apache Spark, Presto, and AWS Athena allow users to run complex queries and analytics directly on data stored in data lakes. These tools can integrate with BI platforms like Tableau and PowerBI to deliver data-driven insights.
Top 4 Use Cases of Data Lakes You Should Know
Augmented Data Warehouse
Data lakes complement traditional data warehouses by storing unstructured and semi-structured data and allowing enterprises to analyze it efficiently. They are used for data that would typically be excluded from structured databases, is not queried frequently, or is expensive to store in a data warehouse.
Advanced Analytics
With data lake management, you get faster access to untransformed data, making it easier for data scientists to use it for machine learning, predictive analytics, and analysis in real-time. Hence allowing businesses to generate insights that were previously inaccessible.
Support for IoT Data
With the rise of IoT devices, data lakes are excellent choices for storing high-volume
high-frequency data from streams and analyze it in real-time, improving operational efficiency and enabling new use cases.
Regulatory Compliance
A centralized repository of an organization’s data makes it easy for organizations to meet compliance requirements by applying role-based security, cataloging data sets, and tracking lineage. Thus leading to simpler processes for subject access and removal requests.
Challenges in Data Lake Management
Reliability Issues
Due to the large and varied nature of data, ensuring consistent data quality and availability can be complex. Without a solid strategy for managing backups, high availability, and failover systems– reliability could suffer.
Security Concerns
Data lakes often contain sensitive information from multiple sources– making security a prime factor to consider. Without the right controls, organizations face risks of unauthorized access, data breaches, and regulatory non-compliance.
Slow Performance
Data lake management– if not properly optimized– can suffer from performance bottlenecks. Slow query response times, inefficient data retrieval, and bottlenecks in processing large datasets can hamper their effectiveness for real-time use cases.
Data Quality and Maintenance
Ensuring that data stored in a data lake remains– clean, consistent, and up to date– is a continual challenge. Without proper data governance frameworks, you risk storing redundant, incomplete, or inaccurate data, which can lead to poor analysis.
Complexity of Data Integration
Bringing in data from diverse sources like– IoT, structured databases, and real-time streams– can be complex. Integration requires careful planning and coordination, especially when different formats, protocols, and schemas are involved.
Conclusion
Data lakes offer immense value to businesses by providing scalable, flexible, and cost-effective solutions for storing and analyzing vast amounts of data. With strong governance, automation, and the right tools, along with the assistance of an experienced cloud consulting company, enterprises can overcome common challenges. Moreover, data lake management allows enterprises to better use data lakes’ potential to drive better decision-making, improve customer experiences, and achieve long-term success.
At Successive Digital, we ensure enterprises utilize the full potential of their data lakes with industry-leading cloud solutions, governance frameworks, and analytics tools. Whether you are looking to optimize data storage, improve accessibility, or get real-time insights, our team of experts is here to guide you every step of the way.
Ready to transform your data strategy?
Contact us today to discover how we can build a scalable, secure, and high-performance data lake solution tailored to your business needs.




